
Authors:
(1) Xiao-Yang Liu, Hongyang Yang, Columbia University (xl2427,hy2500@columbia.edu);
(2) Jiechao Gao, University of Virginia (jg5ycn@virginia.edu);
(3) Christina Dan Wang (Corresponding Author), New York University Shanghai (christina.wang@nyu.edu).
Table of Links
2 Related Works and 2.1 Deep Reinforcement Learning Algorithms
2.2 Deep Reinforcement Learning Libraries and 2.3 Deep Reinforcement Learning in Finance
3 The Proposed FinRL Framework and 3.1 Overview of FinRL Framework
3.5 Training-Testing-Trading Pipeline
4 Hands-on Tutorials and Benchmark Performance and 4.1 Backtesting Module
4.2 Baseline Strategies and Trading Metrics
4.5 Use Case II: Portfolio Allocation and 4.6 Use Case III: Cryptocurrencies Trading
5 Ecosystem of FinRL and Conclusions, and References
3.2 Application Layer
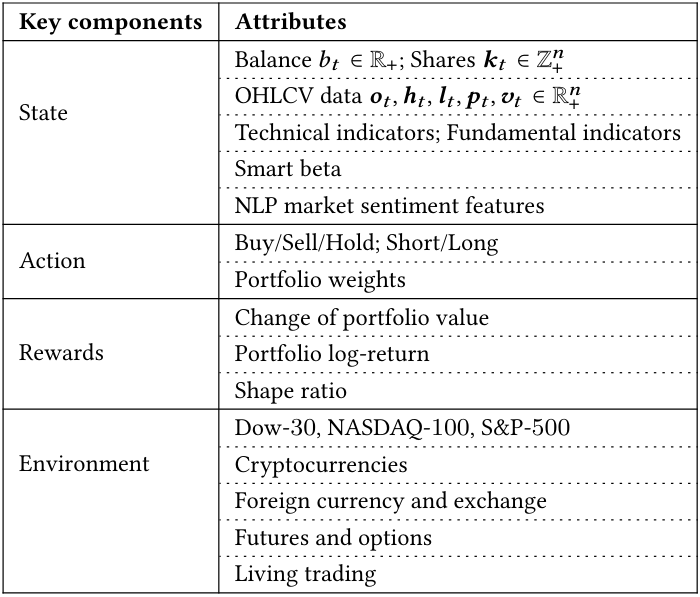
On the application layer, users map an algorithmic trading strategy into the DRL language by specifying the state space, action space and reward function. For example, the state, action and reward for several use cases are given in Table 1. Users can customize according to their own trading strategies.
State space S. The state space describes how the agent perceives the environment. A trading agent observes many features to make sequential decisions in an interactive market environment. We allow the time step 𝑡 to have multiple levels of granularity, e.g., daily, hourly or a minute basis. We provide various features for users to select and update, in each time step 𝑡:

This paper is available on arxiv under CC BY 4.0 DEED license.