

Authors:
(1) Sasun Hambardzumyan, Activeloop, Mountain View, CA, USA;
(2) Abhinav Tuli, Activeloop, Mountain View, CA, USA;
(3) Levon Ghukasyan, Activeloop, Mountain View, CA, USA;
(4) Fariz Rahman, Activeloop, Mountain View, CA, USA;.
(5) Hrant Topchyan, Activeloop, Mountain View, CA, USA;
(6) David Isayan, Activeloop, Mountain View, CA, USA;
(7) Mark McQuade, Activeloop, Mountain View, CA, USA;
(8) Mikayel Harutyunyan, Activeloop, Mountain View, CA, USA;
(9) Tatevik Hakobyan, Activeloop, Mountain View, CA, USA;
(10) Ivo Stranic, Activeloop, Mountain View, CA, USA;
(11) Davit Buniatyan, Activeloop, Mountain View, CA, USA.
Table of Links
- Abstract and Intro
- Current Challenges
- Tensor Storage Format
- Deep Lake System Overview
- Machine Learning Use Cases
- Performance Benchmarks
- Discussion and Limitations
- Related Work
- Conclusions, Acknowledgement, and References
3. TENSOR STORAGE FORMAT
Deep Lake datasets follow columnar storage architecture, with tensors as columns, as shown in Fig. 3. Each tensor is a collection of chunks - binary blobs that contain the data samples. An index map associated with each tensor helps find the right chunk and index of the sample within that chunk for a given sample index.
3.1 Dataset
A sample in a dataset represents a single row indexed across parallel tensors. As opposed to a document storage format, sample elements are logically independent, which enables partial access to samples for running performant queries or streaming selected tensors over the network to the GPU training instances. Multiple tensors can be grouped. Groups implement syntactic nesting and define how tensors are related to each other. Syntactic nesting avoids the format complication for hierarchical memory layout. Changes to the dataset’s schema are also tracked over time with version control, similar to dataset content changes.
3.2 Tensors
Tensors are typed and can be appended or modified in-place. Default access to an index or a set of indices returns the data as NumPy arrays [55]. Instead of storing 1-D data as seen in Parquet [79] or series in Arrow [13], tensors can accommodate n-dimensional data, where typically the first dimension corresponds to the index or batch dimension. Tensors can contain dynamically shaped arrays, also called ragged tensors, as opposed to other statically chunked array formats such as Zarr [52].
3.3 Types
Htype defines the expectations on samples in a tensor such as data type (dtype as seen in NumPy [55]), shape, number of dimensions, or compression. Typed tensors make interacting with deep learning frameworks straightforward and enable sanity checks and efficient memory layout. By inheriting from a generic tensor htype, we can construct types such as image, video, audio, bbox, dicom, and others. For example, a tensor with image htype would expect samples being appended to it to have dtype as uint8 and shape length 3 (i.e. width, height and number of channels). We further expand on the notion of htypes allowing for meta types that support storing image sequences in tensors (sequence[image]), referencing to remotely stored images, while maintaining the regular behavior of a image tensor (link[image]), or even possible cross-format support.
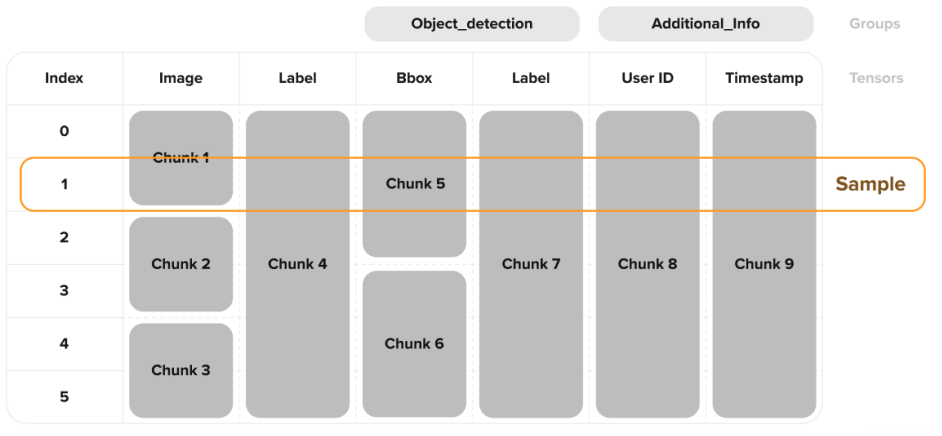
3.4 Memory Layout
A Deep Lake dataset contains a provenance file in JSON format and folders per tensor. A tensor contains chunks, chunk encoder, tile encoder, and tensor metadata. Tensors can be optionally hidden. For instance, hidden tensors can be used to maintain down-sampled versions of images or preserve shape information for fast queries.
Tensors are stored in chunks at the storage level. While statically (inferred) shaped chunking avoids maintaining a chunk map table, it introduces significant user overhead during the specification of the tensor, custom compression usage limitations, underutilized storage for dynamically shaped tensors, and post-processing inefficiencies. Deep Lake chunks are constructed based on the lower and upper bound of the chunk size to fit a limited number of samples. This comes with a trade-off of having a compressed index map that preserves the sample index to chunk id mapping per tensor while enabling chunk sizes in the range optimal for streaming while accommodating mixed-shape samples. One could consider the approach taken in this paper as an optimized trade-off between file system page map and compute-defined map-less array storage system. For practical reasons, a single chunk encoder can be scaled to billions of images while maintaining a 150MB chunk encoder per 1PB tensor data. Further scaling can be introduced by sharding the chunk encoder. Chunks contain header information such as byte ranges, shapes of the samples, and the sample data itself. If a sample is larger than the upper bound chunk size, which is the case for large aerial or microscopy images, the sample is tiled into chunks across spatial dimensions. The only exception to tiling is videos. Videos are preserved due to efficient frame mapping to indices, key-frame-only decompression, and range-based requests while streaming.
3.5 Access Patterns
The tensor storage format is optimized for deep learning training and inference, including sequential and random access. Sequential access is used for running scan queries, transforming tensors into other tensors, or running inference. Random access use cases include multiple annotators writing labels to the same image or models storing back predictions along with the dataset. While the strict mode is disabled, out-of-the-bounds indices of a tensor can be assigned, thus accommodating sparse tensors. However, random assignment over time will produce inefficiently stored data chunks. To fix the data layout, we implement an on-the-fly re-chunking algorithm to optimize the data layout. One of the key access patterns of Deep Lake is shuffled stream access for training machine learning models. It requires random or custom order access while streaming chunks into the training process. This is achieved by involving range-based requests to access sub-elements inside chunks, running complex queries before training to determine the order, and maintaining a buffer cache of fetched and unutilized data. This avoids having a separate compute cluster for running shuffling algorithm [50].
Each tensor has its own chunks, and the default chunk size is 8MB. A single chunk consists of data from multiple indices when the individual data points (image, label, annotation, etc.) are smaller than the chunk size. Conversely, when individual data points are larger than the chunk size, the data is split among multiple chunks (tiling). Exceptions to chunking logic are video data.
Deep Lake format is optimized for maximizing throughput to GPU processing. It includes CPU pre-fetching, decompression or decoding, transformations, and GPU memory transfer in a deep learning framework’s expected layout.
3.6 Storage Providers
Deep Lake can be plugged into any storage provider, including object storages such as AWS S3 [1], Google Cloud Storage (GCS) [3], POSIX compatible file systems, or local in-memory storage. Moreover, it constructs memory caching by chaining various storage providers together, for instance - the Least Recently Used (LRU) cache of remote S3 storage with local in-memory data.
This paper is available on arxiv under CC 4.0 license.