
Brief
In this article, I would like to share an overview of a hard-level task solution published in “Leet code” related to
Task statement
Statements of the task are:
input is lowercase string of english alphabet
string size limited to 40 symbols
any english alphabet symbol in regex have to have match at tested string
symbol ‘.’ expects that it can match any symbol
combination of english alphabet symbols with ‘*’ right after expects that any number of base symbols should occur ( even 0 symbols ) will match
combination ‘.*’ expect any number of any symbols can match
Samples:
isMatch(/*regex*/ “a”, /*string*/ “a”) is true
isMatch(/*regex*/ “a”, /*string*/ “b”) is false
isMatch(/*regex*/ “a”, /*string*/ “”) is false
isMatch(/*regex*/ “a*”, /*string*/ “”) is true
isMatch(/*regex*/ “a*”, /*string*/ “a”) is true
isMatch(/*regex*/ “a*”, /*string*/ “b”) is false
isMatch(/*regex*/ “.”, /*string*/ “”) is false
isMatch(/*regex*/ “.”, /*string*/ “a”) is true
isMatch(/*regex*/ “.”, /*string*/ “b”) is true
isMatch(/*regex*/ “.*”, /*string*/ “badasddsazxc”) is true
Next, we will look at the approaches to the solution: what are the most significant parts of the task to consider?
Precise task overview:
The number of string-to-regular expression matching combinations we can do is huge. Attempting to combine them all and test the match at each of the incoming strings makes the task hard at first glance.
Simplest regular expressions matching
The only way to find the solution is to limit the number of parameters we have. Let’s consider this task with the most primitive subset of regular expressions. Just the simplest regular expression classes will be considered first.
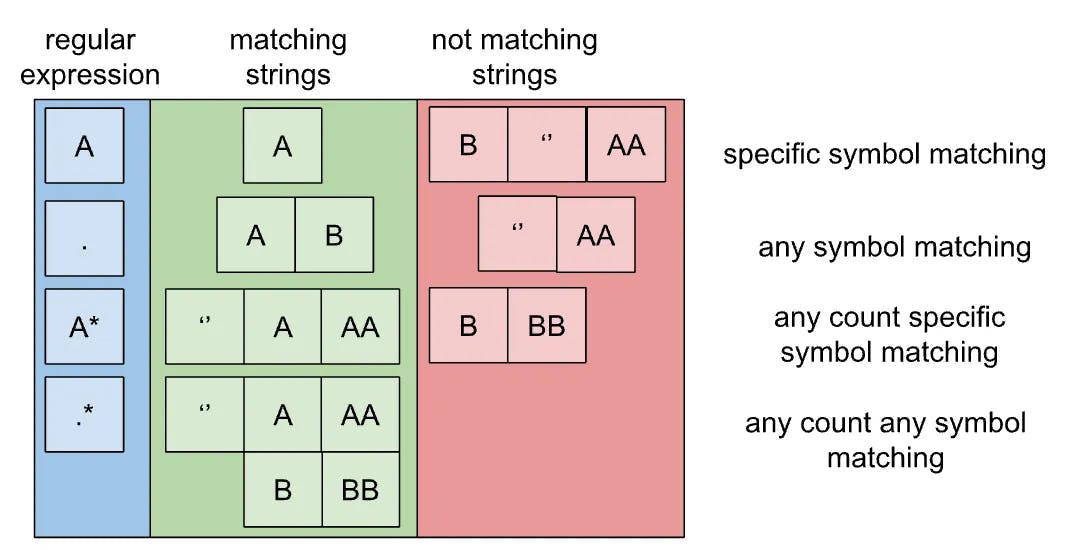
-
Only one specific symbol should match for “specific symbol matching”. Implementation of the algorithm is a comparison of the symbols.
-
Only one symbol should match for “any symbol matching”. Implementation of the algorithm is just counting the number of symbols in the string.
-
All symbols should be equal to the first symbol in the regular expression to match for “any count specific symbol matching”. Implementation is cycled over the string to find that all symbols match the first symbol in the regular expression.
-
For “any count any symbols” matching all of the strings will be accepted.
Now we have ensured that step one of the task solution can be implemented.
Two parts complex regular expressions
The next step is to find a solution for the combination of any 2 possible regular expressions together to find the matching of the string. We can consider all of the combinations of simplest patterns at complex expression, but instead, let’s combine them smartly:
- Let’s consider each of the simplest regular expressions as placeholders of the symbols intervals at string
- these intervals must be continuous
- these intervals cover all of the string data
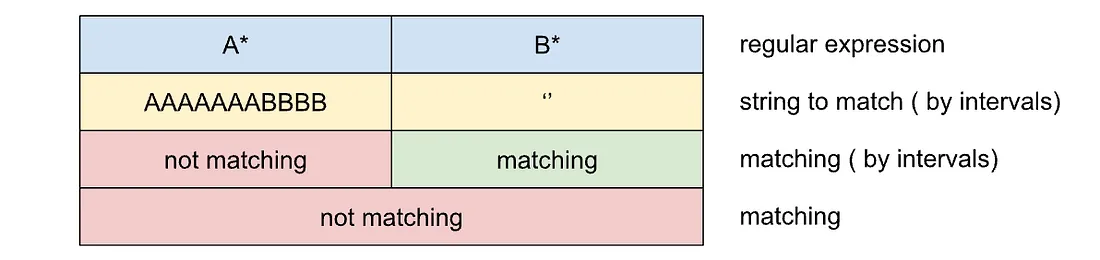
This way we can expect that only 4 combinations of string intervals matching of simplest regular expression exist:
-
no matching at both placeholders
-
matching in the first placeholder only
-
matching at the second placeholder only
-
matching at both placeholders
In the last scenario string matches to regex. In all other scenarios, we can expect that dividing the string into intervals for placeholders can be changed. It means that we can move symbols from one interval to another and vice versa to reach the matching (if possible).
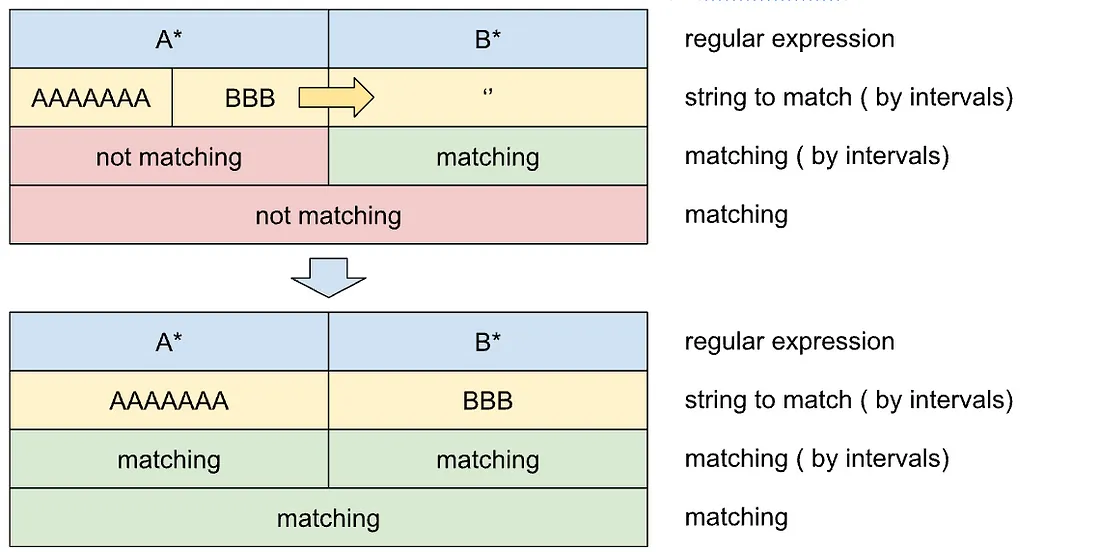
It is possible to make this set of moves of placeholder borders canonical and correct to find the match if it exists.
Initialization of solution
Let’s consider that all of the placeholders have some capacity to match the intervals. For “one symbol regular expression” the placeholder will have a capacity equal to 1. For ”any count symbols placeholders” capacity is unlimited.
It means that it is fair to divide the string into intervals by capacity in the initial stage of the matching algorithm. Let’s put all of the symbols of the tested string to placeholders according to placeholders capacity from left to right.
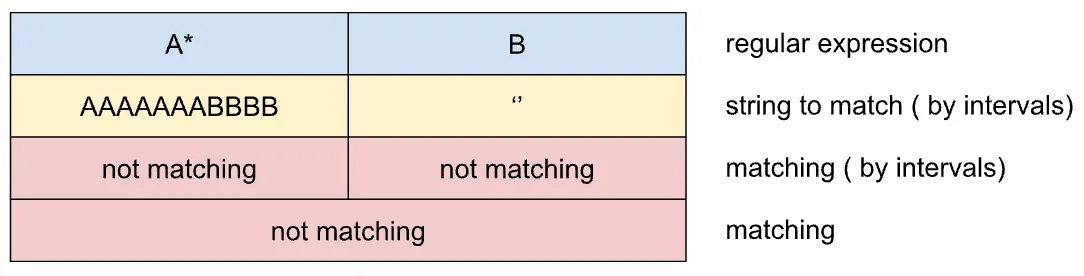
As we can see in the picture, the first interval has unlimited capacity. That is why it contains all of the symbols on the initialization of the algorithm.
This placement is fair:
-
the first matching interval of the string can contain all of the symbols
-
we should try all strings to match first to the simplest placeholder
-
matching to the next placeholder reachable by moving intervals border right to left over the string
-
this move will reflect all possible combinations of sharing symbols between patterns
-
in the case of the first match, it is always possible to find a solution
-
in a case where all moves do not get a match — we can be sure that a match is not possible
So to make the algorithm solid at this state we need to:
-
make initial distribution of string intervals depends on the simplest regular expressions capacity
-
make moving of the border of the intervals right to left at cycle to detect the match
-
the algorithm should be prolonged until a match not found or moves of the interval borders possible
At this point we have step 2 completed: for just 2 intervals we can implement the solution of the task.
Three parts complex regular expression
Now let’s look at dividing the string into 3 placeholders. It is possible to apply the algorithm for 2 placeholders for 3 intervals with small modifications. Next, it is possible to increase the number of placeholders to any count.
As we can see on Picture 5 the first move is from the first placeholder to the next one — left to right. It is the most atomic action we can do, we have no other actions to be made. But why do we select the first placeholder as the source of the move?
-
the first placeholder has symbols to move out
-
next placeholder have capacity to accept the symbol from the first pattern
We can define this criterion as “can move”.
In the next step, we need to define a placeholder to be selected as a source of move. If most right placeholders have a symbol and this symbol does not match the placeholder — then the addition of any symbol will not fix the matching of this placeholder. This symbol can not belong to this pattern. It should be moved.
- not matching most right placeholder that aligns “can move” criterion should be the source of the move
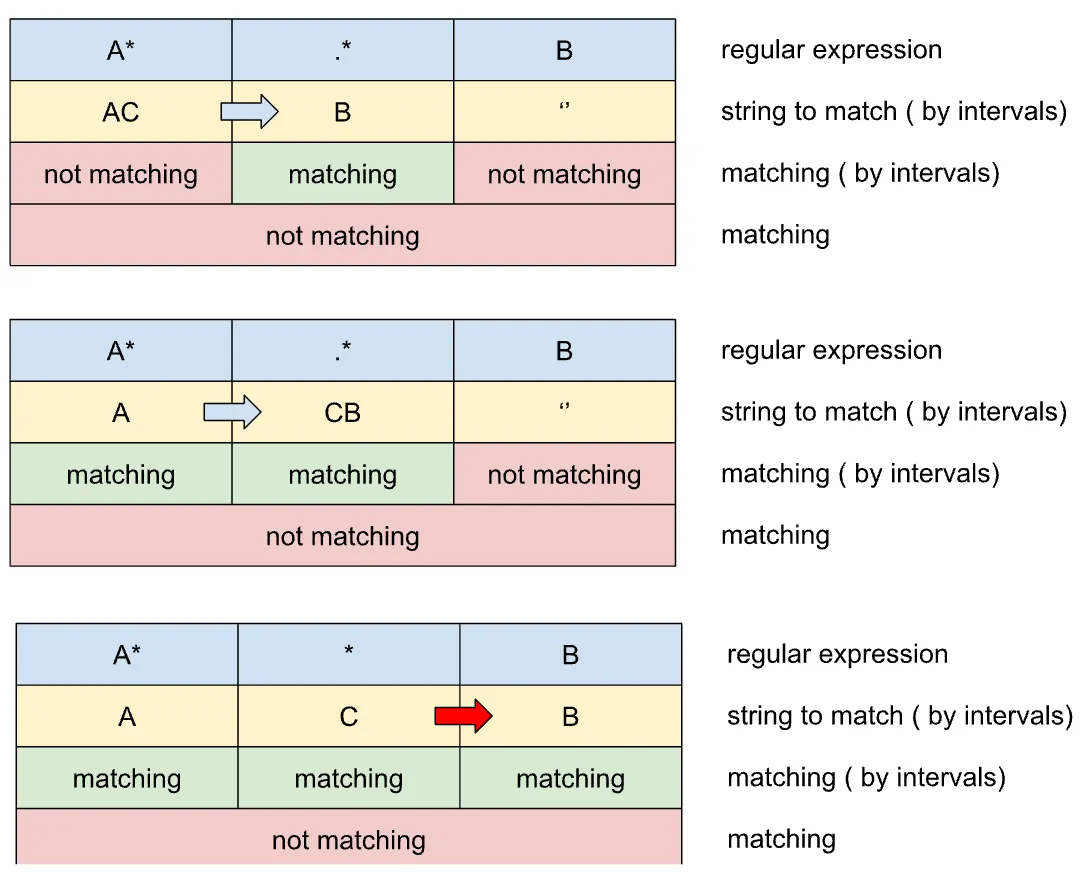
In the second step “source of move placeholder” will be selected by strategy defined above. But if we try to use this strategy for the third step — we will find that no more steps are possible. All placeholders point to the string parts that match to simplest regular expression or to the string without symbols inside.
That is why we need to define additional criteria to detect the “source of move pattern” at the next step that the red arrow in Picture5 shows. It is the special criteria for placeholders that have a match.
Combined placeholder
Let’s consider the first and second placeholders as a combined placeholder. This way we will find that the only option to have a match will be the transition symbol from this combined placeholder to the next placeholder. This is obvious because we have a match at the combined placeholder and do not have it at the next placeholder. It is the same way to act for two placeholders we considered.
But why do we not care to get second and third placeholders as combined placeholders? Without internal movement in this complex placeholder, we can not reach its matching state by moving symbols from outside. That is why we should have equal state placeholders as complex placeholders to correctly use actions from using two placeholders. This means that new criteria should consider this complex placeholder at the beginning of the placeholder collection.
- Most right-matching placeholders with no unmatched predecessors placeholders need to be the source of move at the second strategy.
Algorithm definition
Now, we have all the essential parts together and we can define the algorithm internals:
- Each placeholder stores the simplest regular expression and indicates the string interval of the full string to match.
- During the algorithm, the atomic action involves moving symbols from left to right intervals related to the current and next placeholders.
- To select the source of the move placeholder, two strategies are expected to be applied.
- If the first strategy detects the source of the move placeholder, it will be used. The first strategy requires the placeholder to:
- Be the rightmost placeholder with symbols.
- Point to a string interval that does not match the simplest regular expression at the placeholder.
- Have the capacity at the next placeholder to collect symbols.
- If the second strategy detects the source of the move placeholder, it will be used instead of the first strategy selection. The second strategy requires the placeholder to:
- Be the rightmost placeholder with symbols.
- Point to a string interval that matches the simplest regular expression at the placeholder.
- Have the capacity at the next placeholder to collect symbols.
- Have no unmatched predecessors placeholders.
- The algorithm continues until a full match of all string intervals and simplest regular expressions in placeholders is detected, or no more moves are possible.
Implementation details
We will talk about the implementation of the task in modern C++. There are several points to discuss about the implementation:
- runtime complexity of the solution
- ability to improve solution runtime
- memory footprint
Solution runtime complexity
Let's dive into the runtime complexity of our solution. When considering runtime complexity, we begin by examining each step involved in moving the border of placeholders from one symbol to another. This process involves passing through the symbols one by one. The maximum number of symbols that the count border can pass through is the string length itself. Additionally, the last border cannot be moved at all. Consequently, the worst-case complexity, based on moves, can be defined as O(s²).
However, it's important to note that this complexity is not the final one. At each step, we also need to detect the most right unmatched and matched symbols using strategies one and two. The worst-case complexity of this detection will be linear, denoted as O(r).
Therefore, the total complexity of our solution can be expressed as O(s² * r).
Improving solution runtime complexity
But we can make runtime complexity more effective and reach O(s² * log(r)).
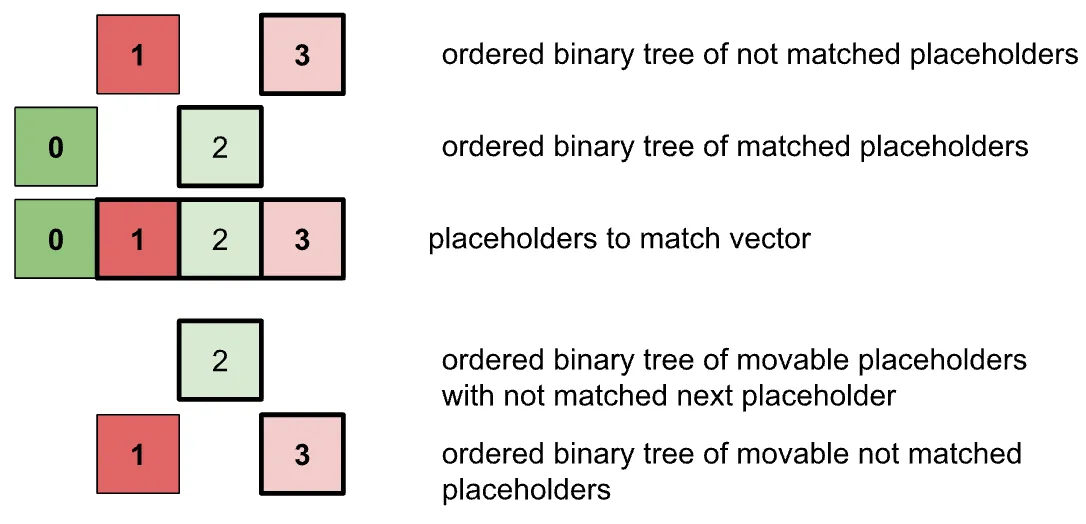
For every step the next move source placeholder needs to be found. Worst case we need to traverse over all of the placeholders to find it. But we can make it better. We can create an ordered binary tree of:
-
unmatched placeholders
-
matched placeholders
-
not matched placeholders that can move
-
matched placeholders that can move and have not matched next placeholder
-
This way the runtime complexity of every insertion and search in an ordered binary tree will be O(log(r)).
-
Detection of move source placeholder for first strategy will contain:
-
detection of first placeholder in not matched placeholders that can move ( O(log(r) )
Detection of move source for second strategy will contain:
-
detection of first placeholder in not matched placeholders ( O(log(r) )
-
detection of lower bound for matched placeholder from first step in matched placeholders that can move and have next placeholder
-
unmatched ( O(log(r) )
-
detection of previous placeholder for previous step ( O(1) )
This is not all about reaching the runtime optimization goal: We need to build these ordered binary trees and be able rebuild them fast.
At every move on the algorithm comes possible to change several parameters:
-
matching state of source of move placeholder
-
ability to move at source of move placeholder
-
ability to move at previous placeholder
-
matching state of next placeholder
We have all of these states at the ordered sets mentioned later. That is why we need to process maximum:
- 4 operations of erasing of placeholders from ordered set
- 4 operations to put it in some other ordered sets
- In both cases we will have complexity for each move equal O(log(r)).
- Simplest regular expression matching improvement
One more area that can increase the runtime is matching of the simplest regular expression in placeholder and string intervals.
Just imagine if we will recount the simplest regular expression matching symbol by symbol at each algorithm step. The complexity of each step of this solution will be linear O(s). This is not an option — we can make it O(1) by using unmatched symbols count and detecting which symbol comes in/out to the string interval that placeholder points.
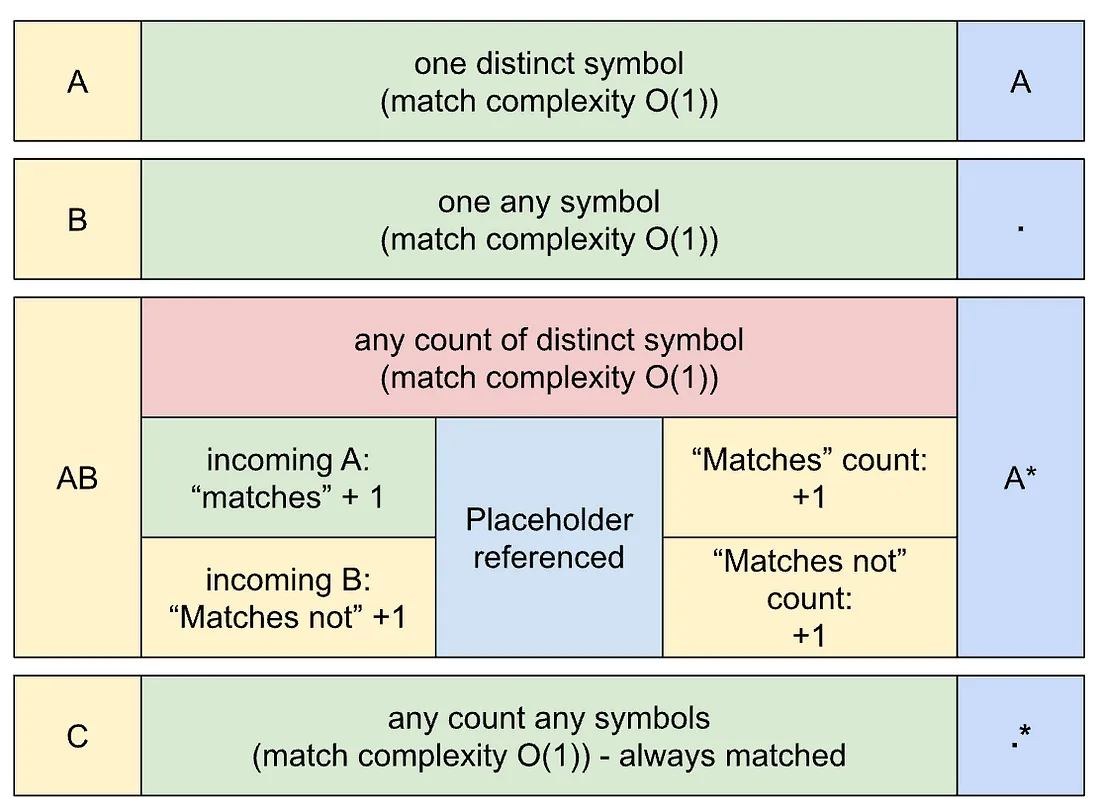
- On each symbol coming we will
- increase not matched symbols count on symbol itself not matched
- decrease not matched symbols count on symbol itself matched
- On not matched symbols count equal to 0 we can detect that simplest regex matched the string
Memory footprint
Now let’s talk about memory footprint. In the best-case scenario, it should be O(s+r). This approach is feasible when we cannot store all intervals and simple regular expressions themselves but only reference certain parts of incoming data.
In C++, the most suitable method for this is utilizing std::string_view classes to hold references to regular expressions and string intervals instead of storing values as string members at placeholders. Even when optimizing for runtime, the memory footprint complexity for both algorithm strategies remains O(s+r). This is due to the fact that the space complexity of an ordered binary tree is O(r).
Conclusion:
Algorithms described in the article have:
- O(s² * log(r)) runtime complexity
- O(r+s) memory complexity
- can be easily implemented at C++
- can be used for matching of string to regular expressions with a limited amount of simplest patterns.